これは Rust その3 Advent Calendar 2019 の24日目のエントリです。 Rustのゼロコスト抽象化が期待どおりに働いていることを、コンパイラが出力した機械語(アセンブリコード)で確認します。
ゼロコスト抽象化とは
ゼロコスト抽象化(zero-cost abstraction)とは、Rustが持つ抽象化のしくみが実行時の追加コストなしに動作することです。 ここでいう追加コストとは、メモリ使用量の増加や実行速度の低下などの、いわゆるオーバーヘッドを指します。
では抽象化とはなんでしょうか? プログラミングにおける抽象化とは、共通な部分を抽出し、その詳細をブラックボックス化することです。 これにより仕様変更に強く、再利用性の高いソフトウェアを開発できます。
Rustが提供する抽象化のしくみには、たとえば以下のようなものがあります。
- ポリモーフィズム:いくつかの型に共通する振る舞い(メソッド)を抽出し、トレイトとして定義する。その振る舞いをどう実現するかは個々の型の実装に委ねられ、メソッドを呼ぶ側では意識しなくてよい
- 高階関数:高階関数とはクロージャを引数にとったり、戻り値として返したりする関数やメソッドのこと。たとえばイテレータや
Option<T>では、それらが包んでいる値を操作するためにmapやfilterなどのメソッドが定義されている。具体的な操作の内容はこれらのメソッドでは定義されておらず、引数にとるクロージャによって実現される
これらのしくみはRustでプログラミングするうえで欠かせないものです。
一般的なプログラミング言語では抽象化のしくみを使うと実行時のオーバーヘッドがかかることがよくあります。 たとえば、ポリモーフィズムを実現するために使われる動的ディスパッチなどがそうです。 (動的ディスパッチについては後ほど説明します)
一方、Rustではこれらをできる限りコンパイル時に解決し、実行時にはゼロコストになるよう、言語自体や標準ライブラリが設計されています。 システム資源の効率的な使用と制御が求められる、システムプログラミング言語ならではの特徴といえるでしょう。
まずは机上で最適化の動作を理解する
Rustのゼロコスト抽象化と呼ばれる機能は、主に以下のものがあります。
- トレイトメソッドとクロージャ
- Future
この記事では前者について見ていきます。 ゼロコストなFutureについては、こちらのRust Blog記事 を参照してください。
以下のコードについて調べます。
// 変数nはi64型。100に束縛する
let n = 100i64;
// 変数o1はOption<&i64>型
// nを指すポインタをSomeで包み、o1を束縛する
let o1 = Some(&n);
// 変数o2はOption<i64>型
// o1がSomeなので、map()メソッドは変数nの値に456を加算してSomeで包む
let o2 = o1.map(|x| *x + 456);
このコードはκeenさんが2016年に書かれた以下の記事で紹介されていたものをベースにしています。
短いコードですがTとして参照型を持つOption<T>型と、ジェネリックな高階関数のmap()メソッドを使用しています。
これらがコンパイル時にどう最適化されて、実行時のオーバーヘッドがなくなるのか調べます。
κeenさんの記事とかぶりますが、まずはコンパイラの最適化の内容を机上で確認しましょう。
列挙型とnullableポインタ最適化
Option<T>型から見ていきます。
今回のコードですが、変数o1はOption<&i64>型、o2はOption<i64>型です。
// 再掲
let n = 100i64; // nはi64型
let o1 = Some(&n); // o1はOption<&i64>型
let o2 = o1.map(|x| *x + 456); // o2はOption<i64>型
標準ライブラリのOption<T>型は列挙型として定義されており、NoneとSomeの2つの列挙子(バリアント)を持ちます。
// https://github.com/rust-lang/rust/blob/master/src/libcore/option.rs
pub enum Option<T> {
None,
Some(T),
}
Rustの列挙型は実行時にバリアントを識別できるよう、ほとんどの場合でタグと呼ばれる通し番号が付与されます。 タグの分だけ余分にメモリを使うわけですから、ゼロコストではありません。
例としてo2の型であるOption<i64>のメモリ上の表現を見てみましょう。
Some(100)のときは以下のようになります。

Noneのときは以下のようになります。

タグを見ればバリアントがわかるわけです。
(1ならSome(i64)、0ならNone)
タグが付与されていることは次のコードで確認できます。
fn main() {
// Option<i64>型が使用するメモリ上のバイト数を表示する
println!("{} bytes", std::mem::size_of::<Option<i64>>());
// => "16 bytes" と表示される。
}
Option<i64>のデータサイズは16バイトだそうです。
i64型のデータサイズは8バイトですが、タグのためにさらに8バイト使っていることがわかります。
しかし、この列挙型ですがタグが不要になることもあります。 それは以下のすべての条件を満たすときです。
- バリアントを2つだけ持つ
- 一方のバリアントはデータフィールドを持たない
- もう一方のバリアントはデータフィールドを持つが、そのデータの全ビットが0になることはない
これを「nullableポインタ最適化」と呼びます。
o2の型のOption<i64>は1.と2.の条件は満たしますが、3.は満たしません。
i64型は0になることがあるからです。
つまりnullableポインタ最適化は適用できません。
一方、o1の型のOption<&i64>は3.も満たします。
&i64は必ず有効なアドレスを指しているので、その値は決して0(nullポインタ)にならないからです。
nullableポインタ最適化を適用できます。
Option<&i64>型のデータサイズを確認すると、期待どおりタグがなくなって、全体で8バイトになっていることが確認できます。
fn main() {
// Option<&i64>型が使用するメモリ上のバイト数を表示する
println!("{} bytes", std::mem::size_of::<Option<&i64>>());
// => "8 bytes" と表示される。
}
メモリ上の表現はSome(&100)ならこうなります。
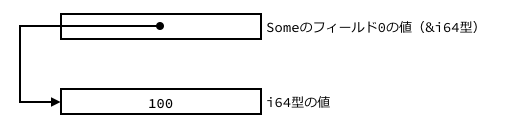
またNoneならこうです。

0(nullポインタ)のときはNoneで、そうではなく、有効なアドレスが入っているときは、Someということになります。
このように列挙型では、特定の条件を満たす場合はメモリ上のオーバーヘッドなしにバリアントの識別が可能になっています。
Option<T>のmap()メソッド
次にOption<T>のmap()メソッドを見てみましょう。
以下のように定義されています。
// https://github.com/rust-lang/rust/blob/master/src/libcore/option.rs
impl<T> Option<T> {
#[inline]
pub fn map<U, F: FnOnce(T) -> U>(self, f: F) -> Option<U> {
match self {
Some(x) => Some(f(x)),
None => None,
}
}
}
map()メソッドはF型のクロージャを引数にとります。
このクロージャはFnOnceトレイトを実装し、T型の値をU型の値へマッピング(変換)します。
map()メソッドには#[inline]アトリビュートがついていますので、コンパイル時の最適化により、呼び出し側のコードにこのコードが埋め込まれるはずです。
元のmap()メソッドを呼び出すコード
let n = 100i64; // nはi64型
let o1 = Some(&n); // o1はOption<&i64>型
let o2 = o1.map(|x| *x + 456); // o2はOption<i64>型
最適化によってmap()メソッドの本体が埋め込まれたコード
let n = 100i64;
let o1 = Some(&n);
// map()メソッドをインライン化
let o2 = match o1 {
None => None,
Some(x) => Some((|x| *x + 456)(x)),
}
コンパイル時にこれと等価なコード(コンパイラの内部表現)が生成されることが期待できます。
さらに、o1にnullableポインタ最適化を適用します。
let n = 100i64;
let o1 = &n; // o1の型がOption<&i64>から&i64へ変わった
//タグではなく、値がnullポインタかどうかでバリアントを識別する
let o2 = if o1 == null {
None
} else {
Some((|x| *x + 456)(o1))
}
実際にはsafe Rustでo1の値をnullポインタに設定することは許されないので、上のコードはコンパイルできません。
ただ最適化の過程では、これと等価な内部表現が作られていると考えられます。
トレイトとして実現されるクロージャ
o1がシンプルな型になり、map()メソッドもインライン化されました。
次はクロージャのところがどうなるか見てみましょう。
// クロージャを定義して引数o1に適用する
(|x| *x + 456)(o1)
クロージャは「無名関数」と自由変数を捕捉した「環境」で構成されます。 コンパイラはクロージャの定義に出会うたびに、クロージャの環境を表現するための匿名型を生成します。
// クロージャの環境となる匿名型
struct AnonymousType;
このクロージャはなにも捕捉しないので環境は空になっています。(データフィールドがありません)
そしてクロージャの無名関数の部分はトレイトメソッドとして実装されます。
// |x| *x + 456 のコンパイラ内部表現を擬似的なコードにすると
// このFnOnce実装は&i32型の値を引数にとり、
impl FnOnce<(&i32,)> for AnonymousType {
// i32型の値を返す
type Output = i32;
// 無名関数の本体
extern "rust-call" fn call_once(self, args: (&i32,)) -> Self::Output {
*args.0 + 456
}
}
これを呼び出すと以下のようになります。
let n = 100i64;
let o1 = &n;
let o2 = if o1 == null {
None
} else {
// クロージャの環境を初期化する
let f: FnOnce<(&i32,)> = AnonymousType;
// クロージャを呼び出す
Some(f.call_once(o1))
}
変数fの値は単なる構造体なので、o1などのローカル変数と一緒にスタック領域にアロケートされます。
Rustでは動的にアロケートするメモリ領域としてスタック領域とヒープ領域を使いますが、一般的な話として、スタック領域へのアロケートのほうがヒープ領域のアロケートよりも高速です。
なお今回のAnonymousTypeはフィールドを持たないので、実行時にはなにもアロケートしません。
トレイトメソッドのディスパッチ
次はトレイトメソッドの呼び出しf.call_once(o1)の実行時コストについて調べましょう。
トレイトメソッドの呼び出しは、普通の関数の呼び出しと比べると複雑になります。 なぜなら、そのトレイトメソッドを実装している型がいくつも存在している可能性があり、そのなかから正しいものを選ばないといけないからです。 このような同種のものからひとつを選ぶ出すことを「ディスパッチ」と呼びます。
Rustでは2種類のメソッドディスパッチ方式をサポートしています。
- 動的ディスパッチ:実行時にわかる情報から呼び指すメソッドの実体を選ぶ。柔軟だが実行時コストがかかる
- 静的ディスパッチ:コンパイル時に決まる型で呼び指すメソッドの実体を選ぶ。使える場面がやや限定されるが実行時コストはかからない
結論から言うと、Option<T>のmap()メソッドはクロージャのメソッドを静的ディスパッチします。
ですからゼロコストになるのですが、そのありがたみは動的ディスパッチがわからないと実感できません。
まずは動的ディスパッチについて詳しく説明しましょう。
動的ディスパッチ
動的ディスパッチは実行時にわかる情報から呼び指すメソッドの実体を選びます。 柔軟ですが実行時コストがかかる方法です。 オブジェクト指向言語の多くはメソッドの呼び出しに動的ディスパッチを使用し、静的ディスパッチは行なえません。 Rustでは前述のとおり動的ディスパッチと静的ディスパッチの両方に対応しており、状況に応じて使い分けられます。
Rustで動的ディスパッチを行うときはトレイトオブジェクトを作成します。 トレイトオブジェクトは同じトレイトを実装してる複数の型を統一的にあつかえるしくみです。 たとえばひとつのベクタに複数の型の値を混ぜて格納したり、関数の戻り値型を条件に応じて変えたりしたいときに便利です。 (もちろんそれらの型が同じトレイトを実装してなければなりません)
トレイトオブジェクトの型は&dyn トレイト名やBox<dyn トレイト名>のようになります。
&やBoxといったポインタ経由でしか使えないことに注意が必要です。
このポインタはfatポインタと呼ばれ、値を指す通常のポインタに加えて、vtableという内部データ構造へのポインタを持っています。
vtableはメソッドの名前と実装コードのアドレスが対になった辞書で、vtableを検索することで呼び出そうとしているメソッドの実装を見つけられます。
f.call_once(o1)を動的ディスパッチで実行するときは、以下のような手順になるでしょう。
let f: &dyn FnOnce<(&i32,)> = &AnonymousType;
// vtableから対象のメソッドを見つける(擬似的なコード)
let m: &fn(&i64) -> i64 = find_method(f, "call_once", (&i64,), i64);
// メソッドを呼び出す
m(f, o1);
動的ディスパッチではvtableのためにメモリを少し多く使用しますし、実行時間もfind_method()の分だけ余分にかかることになります。
静的ディスパッチ
静的ディスパッチは、コンパイル時に決まる型で、呼び出すメソッドの実体を選びます。 使える場面がやや限定されますが実行時の追加コストはかかりません。
Rustで静的ディスパッチを行うときはジェネリクスを使います。
また関数の引数の型としてimpl トレイト名を指定したときも静的ディスパッチになります。
(引数位置のimpl トレイトはジェネリクスの糖衣構文です)
先ほどOption<T>のmap()がクロージャに対してジェネリックなメソッドとして実装されていることを見ました。
このことからmap()は静的ディスパッチを行うことがわかります。
静的ディスパッチではコンパイル時にジェネリックな型を解決し、その型を当てはめた専用のメソッドを作ります。
Option<T>の元の実装
impl<T> Option<T> {
pub fn map<U, F: FnOnce(T) -> U>(self, f: F) -> Option<U> {
match self {
Some(x) => Some(f(x)),
None => None,
}
}
}
実際の型を当てはめた専用のメソッドを作る
pub fn map_i32_anonymous_type(self: &i32, f: AnonymousType) -> Option<i32> {
match self {
Some(x) => Some(f(x)),
None => None,
}
}
fの具体的な型が分かったので、どのトレイトメソッドを呼ぶのか自然に特定されます。
トレイトメソッドが特定された
pub fn map_i32_anonymous_type(self: &i32, f: AnonymousType) -> Option<i32> {
match self {
Some(x) => Some(AnonymousType::call_once(f, x)),
None => None,
}
}
静的ディスパッチを私たちのコードに適用します。
let n = 100i64;
let o1 = &n;
let o2 = if o1 == null {
None
} else {
let f = AnonymousType;
// トレイトメソッドの呼び出しが、静的ディスパッチの働きで
// ただの関数呼び出しに変わった
Some(AnonymousType::call_once(f, o1))
}
さらに今回のクロージャは一ヶ所からしか呼ばれておらず、また本体が十分に小さいので、インライン化が期待できます
let n = 100i64;
let o1 = &n;
let o2 = if o1 == null {
None
} else {
// AnonymousType::call_once()は一ヶ所からしか呼ばれず
// また本体が十分小さいため、インライン化される(はず)
Some(*o1 + 456)
}
コンパイル時の最適化は以上になります。 Rustの抽象化のしくみを使ったコードが、ゼロコスト抽象化に関連する最適化によって、実行時のオーバーヘッドが最小のコードへと変換されました。
アセンブリコードで確認する
それではRustコンパイラが生成したアセンブリコードの内容を確認しましょう。
Rustのバージョンなど
今回は以下のRustバージョンとターゲットを使用しました。
- Rust 1.40.0(2019年12月リリース)
- x86_64-unknown-linux-gnu
$ rustc -Vv
rustc 1.40.0 (73528e339 2019-12-16)
binary: rustc
commit-hash: 73528e339aae0f17a15ffa49a8ac608f50c6cf14
commit-date: 2019-12-16
host: x86_64-unknown-linux-gnu
release: 1.40.0
LLVM version: 9.0
試してはいませんが他のターゲット(macOS、Windows、ARM上のLinuxなど)でも同様の効果が得られるはずです。
確認に使ったコード
元のコードそのままですと、入出力がないためコンパイラの最適化によって全体のコードが削除されてしまいます。 (なにも仕事をしないアセンブリコードが生成される)
そこで以下のような修正を施しました。
- 必要なコードが削除されないよう、コマンドラインから入力をとり、計算結果をターミナルに出力する
- アセンブリのコードを見つけやすいように、何ヶ所かに
println!()を挿入した
fn main() {
println!("let n");
// 変数nはi64型。コマンドライン引数から受け取った数字に束縛する
let n: i64 = std::env::args()
.nth(1)
// コマンドライン引数(String型)をi64型に変換する
// 変換できないときは"invalid number"と表示して実行を打ち切る
.map(|s| s.parse().expect("invalid number"))
// コマンドライン引数がなかったら"missing argument"と
// 表示して実行を打ち切る
.expect("missing argument");
println!("let o1");
// 変数o1はOption<&i64>型
// もしnが123ならo1はNoneに、さもなければSome(&n)に束縛する
let o1 = if n == 123 {
None
} else {
Some(&n)
};
println!("let o2");
// 変数o2はOption<i64>型
// もしo1がNoneなら、Noneに束縛し
// もしo1がSomeなら、xに456を加算してSomeで包んだものに束縛する
let o2 = o1.map(|x| *x + 456);
// n, o1, o2の値を表示する
println!("n: {:?}, o1: {:?}, o2: {:?}", n, o1, o2);
}
コマンドライン引数として整数をひとつ取りnを束縛。
もしnが123ならo1はNoneに、それ以外ならSome(&n)に束縛します。
コードが少し長くなりましたが本質は変わっていません。
実行結果
# 引数として123を与える(o1はNoneになる)
$ cargo run --release -- 123
let n
let o1
let o2
n: 123, o1: None, o2: None
# 引数として100を与える(o1はSome(&n)になる)
$ cargo run --release -- 100
let n
let o1
let o2
n: 100, o1: Some(100), o2: Some(556)
アセンブリコードを生成する
このコードをコンパイルして、最適化後のアセンブリコードを生成しましょう。
以下のようにcargo rustcコマンドを実行します。
$ cargo rustc --release -- --emit asm -C 'llvm-args=-x86-asm-syntax=intel'
--releaseフラグでゼロコスト抽象化などの最適化を行う--emit asmフラグでアセンブリコードの入ったファイルを生成する-C 'llvm-args=...'フラグでx86アセンブリコードの文法としてIntel形式を指定する。(デフォルトはAT&T形式)
x86アセンブリコードの文法にはIntel形式を指定しました。 Intel形式は一般的なプログラム言語に慣れた人には、ポインタによるメモリアドレス指定などが直感的でわかりやすいと思います。 デフォルトの文法であるAT&T形式は、コンパクトなコードになるので読み慣れた人にはいいかもしれませんが、少し癖があります。
アセンブリファイルはtarget/release/depsディレクトリ配下に出力されます。
拡張子は.sです。
$ exa -l target/release/deps/*.s
.rw-r--r--@ 25k tatsuya 21 Dec 14:35 target/release/deps/optmap-4ee5145a2c1fa529.s
tokeiというRust製のCLOCツール(コード行数を数えるツール)でアセンブリコードの行数を数えてみました。
$ tokei target/release/deps/*.s
------------------------------------------------------------------
Language Files Lines Code Comments Blanks
------------------------------------------------------------------
Assembly 1 884 850 0 34
------------------------------------------------------------------
Total 1 884 850 0 34
------------------------------------------------------------------
入出力があるのでCode部分が850行と長くなっていますが、今回はその中の20行くらいを見るだけですみます。
レジスタとスタック領域の使われかた
Rustではローカル変数はスタック領域に置かれます。
生成されたアセンブリコードを筆者が事前に読んで、main()関数のローカル変数n, o1, o2がスタック領域のどこに置かれるか調べておきました。
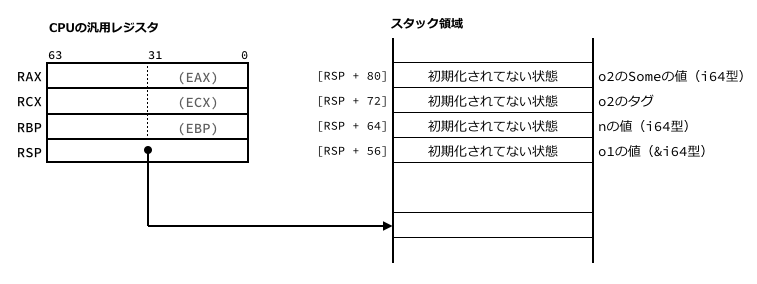
図の右側がスタック領域です。 図の左側にはCPU内にあるレジスタのなかから、今回に関係するものだけを描きました。 レジスタはメモリよりもはるかに高速に動作する一時記憶域で、CPUが持つ多くの命令はレジスタに入ったデータを対象にしています。
RAXとRCXは汎用レジスタで、いずれも64ビットです。
RAX(アキュムレータ)は四則演算の第1引数などに暗黙的に使われたりするRCX(カウントレジスタ)はループのカウントなどにも暗黙的に使われるが、今回は単なるデータの一時置き場になっている
RAXとRCXは32ビットのレジスタとして使うこともできて、そのときは順にEAX、ECXと呼ばれます。
これから見るアセンブリコードにも、RAX(64ビット)とEAX(32ビット)の両方が出てきますが、同じレジスタを指しています。
ちなみにRAXとRCXは16ビットや8ビットのレジスタとしても使えるのですが、今回読む部分には出てこないため、図では省略しています。
RBPとRSPはポインタレジスタです。
いずれも64ビットで、値としてメモリ上のアドレスを保持します。
RBPは汎用ポインタのひとつで、今回は変数o1(ポインタ型の&i64)として使われている。32ビットのEBPとして使うことも可能RSP(スタックポインタ)はスタック領域の先頭アドレスを保持する
Rustで関数を呼び出したり関数からリターンしたりするとRSPの値が増減します。
main()関数のローカル変数n, o1, o2がスタック上に置かれる位置は、RSPからの相対アドレス([rsp + 64]など)で示されます。
x86アセンブラのごく基本的なこと
ごく簡単にですがアセンブリコードの読み方を説明します。
以下のアセンブリコードはポインタであるo1に、&nをセットするためのものです。
lea rbp, [rsp + 64] ; BPレジスタにnの番地をセットし
mov qword ptr [rsp + 56], rbp ; o1にも同じ番地を格納する
左端のleaやmovはCPUに対する命令です。
そのあとにカンマで区切られて操作対象のレジスタなどが与えられます。
これらの操作対象をオペランドと呼び、左から順に第1オペランド、第2オペランドと呼びます。
leaは実行アドレスロード命令で、第1オペランドで指定したレジスタに、第2オペランドのアドレッシングで生成された値(アドレス)をセットします。
上のleaの行をRust風に書くとrbp = rsp + 64になります。
movは転送命令で第2オペランドの値を第1オペランドにコピーします。
上の例では第1オペランドがqword ptr [rsp + 56]となっていますが、[rsp + 56]はアドレス、qward ptrは転送するサイズの指定で、x86系CPUの4ワードポインタである64ビットポインタを表します。
セミコロンから行末まではコメントです。 これ以降は命令の説明を省略しますので、筆者が書いたコメントを読んでください。
nullableポインタ最適化の効果を確認
列挙型のnullableポインタ最適化が働いていることを確認しましょう。 以下のコードのコンパイル結果を調べます。
let o1 = if n == 123 {
None
} else {
Some(&n)
};
o1はOption<&i64>型ですので、nullableポインタ最適化によってi64へのポインタになり、NoneやSomeを識別するためのタグがなくなるはずです。
// 最適化後の擬似的なコード。NoneやSomeがなくなるはず
let o1: &i64 = if n == 123 {
null
} else {
&n
};
アセンブリコード内を123で探すと、以下のコード片が見つかります。
cmp qword ptr [rsp + 64], 123 ; n != 123なら
jne .LBB12_19 ; LBB12_19へジャンプする
mov qword ptr [rsp + 56], 0 ; o1に0(nullポインタ)を格納し
xor ebp, ebp ; BPレジスタも0にする
jmp .LBB12_26 ; LBB12_26へジャンプする
.LBB12_19: ; n != 123なので
lea rbp, [rsp + 64] ; BPレジスタにnの番地をセットし
mov qword ptr [rsp + 56], rbp ; o1にも同じ番地を格納する
.LBB12_26:
nとして100を与えたときについて考えます。
n != 123のときはラベル.LBB12_19以降の命令が実行されます。
そこではRBPレジスタにnが置かれている番地をセットし、さらにo1にも同じ番地をセットしています。
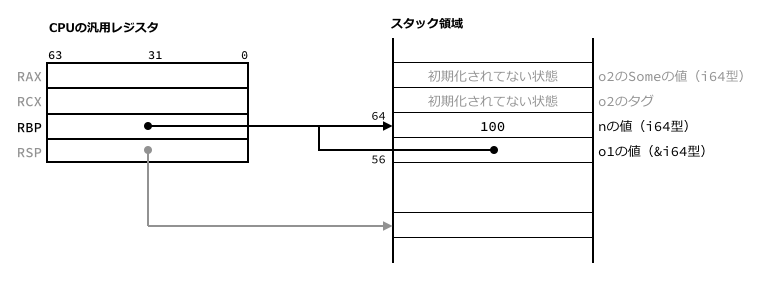
nとして123を与えたときはそれよりも前の命令が実行されます。
o1にnullポインタを意味する0をセットし、RBPレジスタも0にクリアしています。
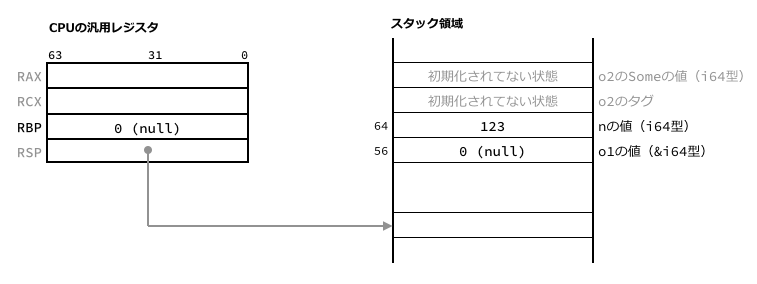
この部分は期待どおりにコンパイルされたことが確認できました。
map()メソッドのインライン化とクロージャの静的ディスパッチ
Option<T>のmap()メソッドに関連する部分を確認しましょう。
元のコードはこうなっていました。
let o2 = o1.map(|x| *x + 456);
クロージャは匿名型とトレイト実装へと展開されますので、最適化前は以下のコードに等しい内部表現になるはずです。
// 最適化なしで展開したコード
// クロージャの環境を表す匿名型
struct AnonymousType;
impl FnOnce<(&i32,)> for AnonymousType {
type Output = i32;
// クロージャの無名関数の実装
extern "rust-call" fn call_once(self, args: (&i32,)) -> Self::Output {
*args.0 + 456
}
}
//
let o2 = if o1 == null {
None
} else {
let f: FnOnce<(&i32,)> = AnonymousType;
Some(f.call_once(o1))
}
そしてこのコードは静的ディスパッチによって以下のように変換され、
// 静的ディスパッチを行う
struct AnonymousType;
impl FnOnce<(&i32,)> for AnonymousType {
type Output = i32;
extern "rust-call" fn call_once(self, args: (&i32,)) -> Self::Output {
*args.0 + 456
}
}
let o2 = if o1 == null {
None
} else {
let f = AnonymousType;
// ただの関数呼び出しになった
Some(AnonymousType::call_once(&f, o1))
}
インライン化によってAnonymousType自体が消滅し、最終的にはこうなるはずです。
// 最適化後の擬似的なコード
let o2 = if o1 == null {
None
} else {
Some(*o1 + 456)
}
アセンブリコード内を456で探すと、以下のコード片が見つかります。
test rbp, rbp ; BPレジスタが0(nullポインタ)かテストし
je .LBB12_27 ; 0ならLBB12_27へジャンプする
mov eax, 456 ; AXレジスタを456にする
add rax, qword ptr [rbp] ; BPレジスタが指すnの値をAXレジスタに加算する
mov ecx, 1 ; CXレジスタを1にする(後でo2のタグをSomeにするため)
jmp .LBB12_29 ; LBB12_29へジャンプする
.LBB12_27:
xor ecx, ecx ; CXレジスタを0にする(後でo2のタグをNoneにするため)
.LBB12_29:
mov qword ptr [rsp + 72], rcx ; CXレジスタの値をo2のタグにセットする
mov qword ptr [rsp + 80], rax ; AXレジスタの値をo2の値の部分にセットする
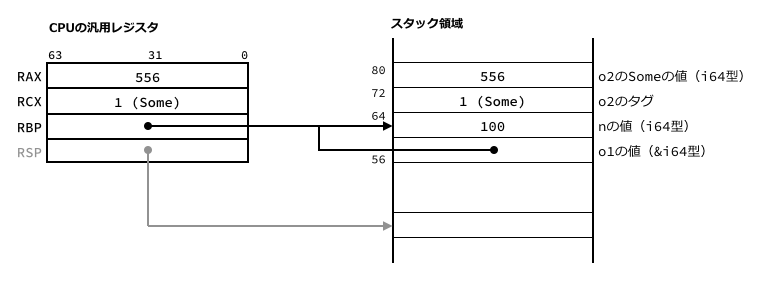
o1がSome(&100)のときについて考えます。
Someのときは前半の命令が実行されます。
そこではRAXレジスタを456にして、RBPレジスタが指すnの値をRAXに加算しています。
結果はRAXレジスタに入ります。
またRCXレジスタにはSomeを表すタグとして1をセットしています。
(o2はOption<i64>型なのでタグを持ちます)
そのあと、ラベル.LBB12_29以降が実行され、RCXレジスタの値がo2のタグへ、RAXレジスタの値がo2のSomeの値部分へコピーされます。
o1がNoneのときはラベル.LBB12_27以降が実行されます。
そこではまずRCXレジスタをクリアしてNoneを表す0にしています。
そのあとはSomeのときと同様に、ラベル.LBB12_29以降が実行され、RCXレジスタの値がo2のタグへ、RAXレジスタの値がo2のSomeの値部分へコピーされます。
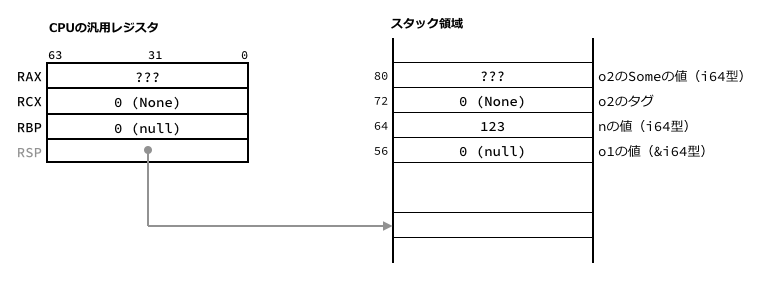
なおNoneのときのRAXレジスタですが、これらの命令の直前の命令群でprintln!("let o2")を実行するための値がセットされているので、o2のSomeの値は無意味なものになってしまいます。
とはいえNoneのときは、そこにどんな値が入っていても読み出されることはないので問題ありません。
この部分も期待どおりにコンパイルされたことが確認できました。
まとめ
高階関数とトレイトによるポリモーフィズムを使ったRustコードをコンパイルすると、手書きしたのと同じくらいシンプルで無駄のないアセンブリコードが生成されました。
- Rustでは抽象化のしくみがゼロコストになるよう、言語自体や標準ライブラリが注意深く設計されている
- ここで言うゼロコストはオーバーヘッドがないという意味。メモリ使用量の増加や実行速度の低下が起きないことを表す
- ゼロコスト抽象化の例として、クロージャの実装とトレイトメソッドの静的ディスパッチを確認した
- また列挙型のnullableポインタ最適化についても確認した
- Rustのゼロコスト抽象化、すごい!